
ABSTRACT
This paper presents "Seed Hypermedia," an innovative architecture for scalable and decentralized collaboration on the web. It integrates elements such as digital signatures, peer-to-peer (P2P) gossip protocols, and distributed hash tables (DHT) to create a robust, secure, and user-managed content system. The core of Seed Hypermedia is a decentralized, indexable network designed to support deep-linking and fine-grained access to content, leveraging IPFS for immutable data storage and CRDTs for managing version-controlled documents. This system enables collaborative editing with a high degree of data integrity through a directed acyclic graph (DAG) of changes, allowing users to maintain ownership and control over their contributions. The architecture promotes a more democratic web environment by decentralizing the indexing and retrieval of content, significantly reducing the reliance on central servers. By integrating advanced cryptographic techniques and a peer-to-peer networking model, Seed Hypermedia aims to empower creators and communities, ensuring permanence, traceability, and scalability in digital content management.
CCS Concepts: • Applied computing → Hypertext / hypermedia creation; • Human-centered computing → Hypertext / hypermedia; • Social and professional topics → Centralization / decentralization; • Information systems → Peer-to-peer retrieval; • Computer systems organization~Peer-to-peer architectures;
Keywords: Seed hypermedia, hypertext system, decentralized architecture, open collaboration
ACM Reference Format:
Gabo Beaumont, Horacio Herrera García, Alexandr Burdiyan, Julio García, and Eric Vicenti. 2024. Seed Hypermedia: bringing scalable collaboration to the decentralized Web. In 35th ACM Conference on Hypertext and Social Media (HT '24), September 10--13, 2024, Poznan, Poland. ACM, New York, NY, USA 6 Pages. https://doi.org/10.1145/3648188.3677050
1. INTRODUCTION
A seed's coating protects its genetic information — sometimes for centuries — until the optimal moment to sprout. It embodies potential — for growth, life, connection, change, and future-shaping. Cryptography leverages a unique, twelve-word "seed phrase" as the basis for a trusted record. Seed Hypermedia aims to unlock the latent potential of decentralized, collaborative digital media.
1.1 Background
Hypertext is a medium for thought and communication. The advent of the web simplified the more complex hypermedia systems developed from the 1960s to the 1980s. The web's emphasis on networking and decentralization democratized access to information, propelling it to the forefront of the hypertext revolution and securing its position as the dominant force.
However, despite its foundational promise, the web has fallen short of its potential as the ultimate medium for thinking and communication. Centralized platforms like Twitter and Instagram dominate, driven by central planning that stifles digital societies’ dynamic and collaborative nature. This centralization impedes innovation and collaboration, undermining the potential of digital media.
Humans need better collaboration and thought tools to solve ever more complex problems. However, the goal of most web content today, basically social media or click-bait media, is to generate advertising by competing for our attention through emotional manipulation.
More than ever, the public sphere has become a platform for advertising instead of a platform for constructive dialogue and critical debate. Conversations are fragmented, divisive, and plagued with disinformation, leading us to polarization.
1.2 Vision
Seed Hypermedia emerges as a solution to fix collaboration on the web within a framework of decentralization and networking. Drawing inspiration from pioneering hypermedia systems like Augment and Xanadu and projects like the Open Hypermedia System from the University of Southampton [7], Seed Hypermedia bridges the gap between traditional hypermedia and the modern web.
1.3 Principles and Goals
Seed Hypermedia marries cryptographic signatures with a promise from the past: a publishing system with fine-grained linking and transclusion capabilities. By integrating decentralized technology with content distribution, Seed Hypermedia empowers creators to collaborate while retaining authorship rights, offering their audiences and communities social media interactivity within a self-curated environment. To achieve these goals, we will follow the principles below:
1.3.1 Open Source Hypermedia System for the Web. Our codebase must be open source if we aim to amplify human knowledge through meaningful collaboration. Open source software empowers users to modify and improve the software, bootstrapping tools that best support their collaborative processes and information workflows. This approach ensures transparency, trust, and security, essential for systems that manage and disseminate human knowledge.
1.3.2 Open collaboration for knowledge communities. People's collaboration should focus on shared goals to build comprehensive knowledge bases needed to address collective challenges rather than an empty competition for consumers attention. By harnessing collective intelligence, distributed communities can effectively pool resources and expertise, creating an environment where innovative solutions can emerge from united efforts.
1.3.3 Decentralization. Detaching identity from third-party servers ensures user autonomy and privacy, promoting a more secure and democratic digital identity framework. Seed Hypermedia prioritizes dissociating user identity from centralized servers in line with the concept that servers should serve merely as infrastructure. By empowering users to control their own identities and authentication mechanisms, we foster a more resilient and inclusive digital ecosystem where individuals have greater autonomy over their personal data and interactions.
1.3.4 Peer-to-Peer Content Distribution. Direct and open content distribution in a peer-to-peer fashion ensures resilience and decentralization, reducing reliance on centralized servers. Together with decentralized identities, we eliminate the problem of central authority controlling access to information.
1.3.5 Respect for Copyrights. Publishing should respect copyrights, balancing authors’ rights with open access and collaboration principles. Seed Hypermedia takes a proactive approach to copyright respect by implementing mechanisms for transparent attribution and licensing of content. By facilitating clear ownership and permissions management, Seed Hypermedia ensures that creators’ rights are upheld while fostering a collaborative culture within the digital ecosystem.
1.3.6 Permanent Information. Information should be permanent, with robust versioning systems to maintain the integrity and history of digital content. Embracing the Long Now concept, which encourages thinking on timescales of centuries or even millennia, Seed Hypermedia aims to ensure that digital content remains accessible and meaningful across generations. By preserving information durably and timelessly, we contribute to a more enduring and inclusive digital heritage for future civilizations.
2. OPEN COLLABORATION
Links are the backbone of online collaboration. Inspired by Ted Nelson's assertion that "everything is deeply intertwingled" [11, p.DM56] and Vannevar Bush's vision of permanently stored associations [3], we have designed a powerful linking system where everything is addressable, reusable, and permanently stored. However, links alone are not enough to augment knowledge communities. Drawing from Doug Engelbart's Augment system [5], we have created an open hypertext document that incorporates advanced provisions to enhance collaborative knowledge work. These enhancements facilitate dynamic interactions, resilient collaboration, and ensure the longevity and accessibility of digital content.
2.1 Open Hypertext Document
Seed Hypermedia documents are one kind of Open Hypertext Document composed of various content blocks1 that can include text, multimedia elements, external web embeds, Embeds and other Hypermedia documents. Each block has a unique identifier that remains constant even if the document is moved or updated. This identifier system facilitates character-level referencing within documents, enhancing collaboration and discussion.
Documents are structured as lists of blocks, with blocks capable of nesting other blocks, forming a hierarchical structure. This organization helps manage complexity, supports cognitive processes, and aligns with human capabilities, enhancing efficiency and comprehension.
Every entity in a document is addressable. URLs can point to a whole document, block, or even a piece of a block. This fine-grained linking enables fair content reuse, allowing documents to bring in pieces from other documents while keeping the attribution and original context and maintaining a bi-directional link between the two. These are commonly called ‘transclusions [12, preface, p.5, fn.2] in hypermedia systems, but Seed Hypermedia uses the term Embeds. This is different from copying. A copy isn't inherently linked to its original and can be changed in the duplicate version.
Unlike HTML and other related formats, links in a Seed Hypermedia Document have a designated space and are not "sprinkled" all over the text. Instead, there is a global map of named links for the whole document, and every time a link is used in the content, it is used as a reference from this global map. This is very similar to how scientific papers have a separate reference section.
When reading a document, a user can access backlinks — mentions from other documents of their linked-data graph pointing to this document. From a side panel, the user can view different documents at the same time.
Every publication is content-addressable and replicated over the network, making broken links less possible, as any peer on the network can become a content provider. This is a crucial difference from what we're used to with links on the Web, which are location-based and prone to disappear.
This approach is based on the web of names system where every content has a convenient and easy name, a UUID that allows us to track content that changes with time, and the hashes (SHA1) that allow total precision in managing content[1].
The document hierarchy in Seed Hypermedia enables the implementation of innovative viewspecs, which provide flexible and powerful ways to navigate and manage complex documents. Inspired by Doug Engelbart's Augment system [6], viewspecs allow users to manipulate the display of document contents based on various parameters, facilitating better comprehension and organization. Key features include bird's eye view, clipping, truncation, and outline views. These tools enable users to decide how to view a document, such as showing only the first sentence of each paragraph, collapsing or expanding sections, and applying content filters. This approach allows users to gain a high-level overview and then zoom in on specific areas of interest, enhancing their ability to study, modify, and understand the document's structure and content effectively.
Additionally, viewspecs can be embedded into links, allowing different document views to seamlessly incorporate into other documents. This flexibility not only aids in better content management but also promotes a dynamic and interactive hypermedia experience by allowing users to tailor the visibility and structure of information to their preferences.
While documents serve as the primary medium for content creation, offering a solid and structured way of sharing knowledge, we also recognize the need for spontaneous and ephemeral conversational content. This is where comments come into play. Comments allow for dynamic and quick exchanges of ideas, serving as a space for academic discourse and critical thinking. They are the lifeblood of intellectual conversation, facilitating ongoing dialogue and fostering deeper understanding.
2.2 Collaborative Workflows
Our hypermedia system is designed to enhance open collaborative and editorial workflows through structured, version-controlled documents, deep linking, and dynamic, fine-grained permissions. Cryptographic signatures and peer-to-peer distribution allow authors to maintain sovereignty over their contributions, promoting an environment conducive to networked improvement communities.
2.2.1 Collaborative Editing. Collaborative editing is facilitated by allowing any account to introduce and declare ownership of a new branch. The system's dynamic and fine-grained permissions allow precise control over who can directly edit documents or suggest changes. These permissions can be adjusted dynamically, providing flexibility and control over collaborative processes. The permissions are engineered cryptographic allow lists and capabilities-based security. Built-in features such as decentralized identity and version control enable users to see how the document has evolved and how every user has contributed to the different versions.
2.2.2 Suggested Changes. Suggested changes allow users to propose modifications to documents they do not have permission to edit or prefer to suggest changes even if they have the necessary permissions. They do not alter the document's official version but are presented to others as recommendations. This mechanism encourages community input and peer review, fostering an environment where improvements can be discussed and refined before being officially adopted.
2.2.3 Branching alternative perspectives. Branching or forking a document allows users to create independent versions of documents when changes are already part of another document. This capability supports innovation and experimentation by enabling users to explore new directions or improvements without impacting the original document. It not only allows for the introduction of new perspectives into collaborative projects but also fosters diverse contributions. If a fork develops content that could enhance the original document, users can merge this content back into the original.
2.2.4 Conversations and Discussions. Our system also supports argumentative discussions by allowing users to suggest changes and engage in debates about the content. These discussions can occur within the context of suggested changes, where users can propose modifications and provide arguments for or against them. This encourages a thorough review process and critical thinking, as users must justify their suggestions and consider alternative viewpoints.
2.2.5 Knowledge Communities. Seed Hypermedia's networked infrastructure fosters collaboration among diverse groups from different knowledge fields, work groups, and corporations. This interoperability between various domains enhances our ability to find innovative solutions to increasingly complex challenges.
By establishing knowledge communities that engage in collaborative dialogue within a distributed repository of documents, we facilitate the emergence of structured knowledge unique to each field. Leveraging open-source software enables these communities to continuously refine and enhance their collaboration tools, significantly accelerating the achievement of their collective objectives.
3. DECENTRALIZED HYPERMEDIA SYSTEM
Our aim is to revive the foundational vision of the web as a domain for uninhibited collaboration, where distributed communities can unite and innovate without the constraints imposed by centralized platforms. Centralized hypermedia applications such as Notion, Microsoft Teams, and Google Docs have demonstrated that they can offer secure and private collaborative experiences; however, they concentrate control and data within a single entity. Conversely, popular public platforms like Twitter and Instagram often wrest content ownership from creators, aligning it with their centralized agendas and economic priorities.
To actualize this vision of an open hypermedia system, we leverage public key cryptography, ensuring robust identity management that bypasses the need for traditional, centralized databases. Additionally, we incorporate a sophisticated version control system that supports content addressability, along with Conflict-free Replicated Data Type (CRDT) algorithms. These technologies facilitate local[8], rich, interactive experiences by synchronizing document states across a network of computers. By integrating peer-to-peer connectivity, we enable direct interactions between peers, further decentralizing the architecture and reducing reliance on central servers.
This approach not only empowers creators by returning control of the content to them but also fosters a truly collaborative environment that mirrors the decentralized, interconnected nature of the original web. Through these innovations, we strive to create a hypermedia system that is both open and scalable, capable of supporting dynamic, distributed collaborations.
3.1 Identity and Proof of Authorship
In our decentralized hypermedia system, identity management ensures secure, verifiable user interactions. Instead of traditional centralized identity mechanisms, our system relies on cryptographic keys to establish and verify user identities.
3.1.1 Public Key Infrastructure. At the core of our identity system is the use of public-key cryptography, which is fundamental to enhancing security and user autonomy within our decentralized framework. Users are empowered with a unique, twelve-word ‘seed phrase’ that establishes a trusted record, while the corresponding private key acts as a personal signature. This private key is used to sign changes and actions, offering a robust mechanism for authentication and non-repudiation.
The public key, derived from this seed phrase, is broadcasted to enable other users within the system to verify the authenticity of actions performed by the account holder. All interactions, changes, and data within the system are cryptographically signed with the user's private key, ensuring that they are tamper-proof and verifiable.
This method not only eliminates the need for traditional password-based authentication, which is vulnerable to various security threats but also significantly enhances the security environment for user interactions, adhering to the principles of user control inherent in decentralized systems.
3.1.2 Key Management Challenges. Managing cryptographic keys in a decentralized environment presents unique challenges. Key revocation, for instance, is problematic because invalidating a key also invalidates all content previously signed with that key. This would be unacceptable in a system where content is meant to be permanent and reusable. Our solution involves a careful balance between usability and security, where users are encouraged to securely store and back up their keys. Additionally, we support key rotation to allow users to replace compromised keys without losing their entire identity. This approach requires users to rebuild trust through social proofs and other mechanisms, which, while cumbersome, are necessary for maintaining security.
3.1.3 Web of Trust and Address Book. To prove their identity, users can publish cryptographically signed claims on various third-party platforms (social media, forums, DNS, HTTPS). In addition to that, users can vouch for the veracity of the identity of other users by broadcasting signed claims on the network [13]. The strength of one's identity is proportional to various proofs it has, but overall it is subjective to each individual counterparty: e.g. Alice can decide to trust Bob because she knows him personally, even if Bob does not have any signed proofs at all.
Each user maintains an Address Book that aggregates various identities under an arbitrary name, similar to the address book on a mobile phone. This address book is public, helping to spread trust across the network.
3.2 Version Control and CRDTs
The system employs IPFS [2] for immutable data storage, leveraging content-addressable identifiers (CIDs) and CRDTs to manage version-controlled documents. Document changes are tracked via cryptographically signed patches, facilitating collaborative editing while preserving data integrity through a directed acyclic graph (DAG) of changes. We build upon ideas from Bitcoin [10], BitTorrent [4] and git to achieve collaborative version control in a decentralized network.
3.2.1 Immutable Data Storage with IPFS. Seed Hypermedia content can be modified by many people over time, but it is all stored as permanent data. Seed Hypermedia system uses IPFS ‘Blobs’, immutable data entries identified by a content-addressable ID (CID), to manage these changes. Three key concepts for handling these changes are Changes, Versions, and Refs.
3.2.2 Changes and Versions. A Change describes how the data of a Document may change. Each Change may contain:
Patch: Details of the new content.
Deps: The dependent Changes that this Change is building upon.
Account ID: Identifies who created this Change.
Signature: The cryptographic proof that the Account made this Change.
Each Change is identified with an ID, a CID derived by taking a checksum of the Change data. To determine the current state of a Document with a given Change ID, you would take the following steps:
Order the dependent changes and compute the state of each of them.
Combine the dependent changes.
Apply the patch of the current change.
A ‘Version’ represents an immutable view of a document, explicitly referencing a set of changes. This system ensures that the document's history and state are preserved and traceable through its changes.
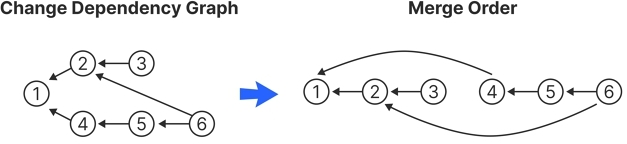
3.2.3 Directed Acyclic Graph (DAG) and Change Ordering. A DAG of changes defines a partial order between changes, expressed with their dependency links: a dependency change must have happened before the dependent change.
To understand how changes should be merged, it is necessary to understand the total order of Changes in a Version. The algorithm sorts first by topological order and timestamp and then by change IDs in the case of ties. The topological total order is achieved by performing a depth-first preorder traversal of the DAG of changes and sorting any siblings by the previous timestamp rules.
Timestamp Order uses the Unix timestamp expressed in microseconds carried by each change, which MUST be greater than any timestamp of any of its dependencies. In case of system clock skews, similar rules to those proposed by the Hybrid Logical Clock paper [9] are used: the lowest 16 bits of the int64 timestamp act as a logical counter, incremented (up to a threshold) until a value greater than any previously seen timestamp is obtained. If the skew exceeds the threshold, the operation is aborted, and an error is thrown, indicating a significant system clock discrepancy or a dependency change with an unrealistic future timestamp (normally prevented when applying a remote change to the local state).
Given any two changes, they are first ordered by their timestamp value, as shown in Figure 1. If the timestamps are equal (unlikely due to microsecond precision), the tie is broken by comparing the changes’ IDs lexicographically. The same author ID must avoid creating changes with identical microsecond timestamps, achievable given the microsecond precision, even for users with multiple unsynchronized devices.
3.2.4 Publishing documents and Refs. A ‘Ref’ is a Blob pointing to a specific version of a document at a given time, defined by a unique document ID (docID) saved in the Ref. New Ref Blobs with the same docID are created as documents evolve, and older ones may be discarded. Each Ref includes the docID, the owner's account ID, the current state changes, and a signature. Refs can also include additional metadata like the total change count and the latest version snapshot.
Each document has a unique ID that is cryptographically related to the owner, preventing hijacking in the peer-to-peer network. The docID is a 22-character alphanumeric string derived from the owner, creation timestamp, and random information, hashed and encoded using Base-58. When referencing a document ID, the signature should be verified against the owner's account ID to ensure authenticity. To publish a document, a Ref is created pointing to a set of changes, which may be generated during the publishing process.
The Seed Hypermedia system also supports local drafts, allowing changes to be made and reviewed before being published as a final version, although they are not part of the network. Explicit forking or branching of documents by creating a ref with a new docID that references existing changes from another doc.
4. SCALABLE AND PERMANENT NETWORK
The Seed Hypermedia Network consists of peers who talk to each other directly or via relay services. Peers replicate and store the content of their interest. Every app, website, or gateway instance is considered a Node. Sites are special peers that also act as web publishers. We've chosen to use IPFS and Libp2p as the foundation of our network, and we rely on multiple ecosystem components.
4.1 Peer-to-Peer Discovery and Connection
To get started with Hypermedia, a peer will need to connect with a set of other peers to get acquainted with the network and find some relevant content. The most common way to join the network is to connect to a known domain over HTTPS and collect Libp2p routing information. Next, if you have a Document ID or Account ID you are interested in, you may bootstrap the Libp2p Amino DHT and use that to find peers who proclaim to have that content. Additionally, people may share routing information directly over email or messaging apps, to perform an initial connection.
Once you connect to a peer over Libp2p, you will use the built-in service discovery mechanism to upgrade your connection to the Seed Hypermedia protocol, which is built on gRPC.
4.2 Hypermedia Sync
When two Seed Hypermedia peers are connected, they regularly exchange information through the following process:
A peer may optionally introduce themself as an Account using a signature, which allows other peers to associate their trust information with this peer. Then, each peer will request certain content. These will include all docs and accounts to which they are currently subscribed and content they are interested in loading at the moment. In exchange, they will receive the Ref for each piece of matched content. Each peer will also broadcast a list of Document Refs and Contacts, along with metadata, including the title.
At this point, each peer has exchanged all of the relevant Refs between each-other. These Refs contain the CIDs of the latest Change Blobs for all of the content that they can exchange. Peers will use a set reconciliation algorithm to determine the full list of dependent Change CIDs they must resolve.
Last, each peer will know exactly what Blobs they need, which are synced using the BitSwap protocol from IPFS. This enables any IPFS node to resolve this data, although their current connection is probably the one best able to respond.
4.3 Content Discovery
When a node broadcasts during the sync process, its peers may find new content that they were not already aware of. When attempting to load a Document from this list, a peer will start by initiating a sync with its current peers, which includes this Document in the request phase.
If the current peers do not have the related changes for this Ref, or if the node wants to make an effort to get a newer Ref for this Document, a peer will look up this document ID on the Amino DHT to find peers who are broadcasting it and repeat the sync process. By looping through this process with known peers and new connections, people can discover new content on the network without being inundated with spam.
4.4 Web of Trust
It is vital to build upon known reputations to trust who you connect with. Users have the functionality to “Add a Contact” for a given Account, which performs several actions:
Consent for persistent connections to nodes who authenticate as this Account
Subscribe to the Profile Document of this Account
Sign and broadcast a Connection Blob for this Account to indicate trust in the network.
Connection Blobs are shared during the Sync process, allowing other nodes to see who trusts. They may contain additional metadata, including associations with domains and social networks (along with the signed proofs for these associations).
4.5 Propagation Strategy
Content in the Seed Hypermedia network must be ephemeral enough to allow bad content to be flushed while ensuring permanence for content people care about.
The only way to guarantee permanence is to save it yourself. If anybody in the network chooses to archive some content, it will be retained. When some content is frequently linked, it will be archived in a viral pattern, and it becomes effectively permanent.
Nodes may privately choose to delete or block certain content from their node to prevent it from entering their system again. This is appropriate for illegal or undesirable content. A node may privately mark certain content as restricted, which will be archived permanently but will not be distributed to other peers. This may be appropriate for content that might be copyrighted, for example.
Each node may also decide what content is advertised during the broadcast phase of synchronization. By choosing what content is broadcasted, blocked, or restricted, each node can participate in moderating the content on the network and archiving important content for themselves and the world. By including the trust information from known peers and accounts, we can have high confidence that good content will spread and be preserved while bad content will be suppressed.
5. CONCLUSIONS
We believe we have been able to marry the strengths of past hypermedia systems with modern decentralized technologies, bringing openness and collaboration to the web. Realizing the promises made by Xanadu and Augment is within reach.
This local-first architectural approach significantly reduces reliance on central servers. It enhances the user experience by enabling clients to operate without continuous server communication, giving instant response from the computer and control and ownership over the user's data.
However, the adoption of a cryptographic framework introduces challenges, particularly in the management of private keys. In a system without central servers, the loss of keys by users complicates security management, with no straightforward remedies readily available. To address this, we are exploring innovative solutions such as social revocation, where community and network-based approaches may help in managing and recovering lost credentials.
Another challenge of peer-to-peer systems is mobile support. In these networks, nodes act as both clients and servers. This makes mobile support difficult because these devices are notoriously bad servers as they run in constrained network environments and are optimized for low power consumption. To support mobile devices while ensuring security, the Seed Hypermedia app will keep a private identity for signing content. This content will be backed up and distributed by other nodes, such as a site, which runs as a web server.
We are confident that we can offer the same interactivity as social media. This is especially important for publishers who want to bypass gatekeepers, maintain a direct relationship with their audience and communities, and retain control of their copyrighted content. This empowerment is crucial in an era when content creators seek greater independence from platform constraints.
Looking ahead, our focus will shift towards enhancing mechanisms to protect digital rights within a peer-to-peer framework, including copyright metadata management. Moreover, we recognize the potential of micropayments as an innovative business model alternative to traditional advertising. This model would support seamless transactions for royalties, providing a sustainable revenue stream for creators.
ACKNOWLEDGMENTS
We would like to acknowledge Mark W. Anderson and Cesar García for their invaluable editorial work and their help in submitting this paper to the Hypertext Conference, marking our first contribution to the research community in this field.
Do you like what you are reading? Subscribe to receive updates.
Unsubscribe anytime